
时间:2023-06-26 点击量:
建造环境(BERL)课题组商文哲博士在中科院二区期刊《Building and Environment》(JCR Q1, IF=7.093)发表论文,研究基于强化学习的空气净化器智能运行策略以获得更好的空气品质和更高的能源利用效率。

一. 题目
Developing smart air purifier control strategies for better IAQ and energy efficiency using reinforcement learning
基于强化学习开发空气净化器智能控制策略以提高室内空气质量和能源效率
二. 作者
Wenzhe Shang(商文哲), Junjie Liu(刘俊杰), Congcong Wang(王聪聪), Jiayu Li(李佳钰), Xilei Dai(戴希磊,通讯作者)
三. 研究亮点
• 建立了一个考虑随机因素的房间模型来描述室内空气质量变化过程。
• 在保持室内PM2.5浓度相同的情况下,强化学习策略1 (RL-1)可使空气净化器节能43%。
• 强化学习策略2(RL-2)节能40.6%,同时可以使室内PM2.5平均浓度降低3.7%。
• 强化学习能够适应影响室内空气质量的随机环境参数,达到更好的控制效果。
四. 研究背景
大量流行病学研究表明,PM2.5的暴露与儿童过敏、老年人心率变异性(HRV)、慢性阻塞性肺疾病(COPD)、冠心病(CHD)等较高健康风险呈正相关。2013年,PM2.5被列入第一类致癌。而人们大约90%的日常生活是在室内度过的,因此将室内PM2.5浓度维持在可接受的水平是至关重要的。根据《中国建筑节能年度发展研究报告2021》,维持室内空气质量最经济的方式是自然通风,并辅以空气净化器。
在雾霾天气中,自然通风很难使室内PM2.5浓度保持在可接受的水平,因此中国家庭中需要广泛普及空气净化器。2019年的一项调查显示,虽然中国有很多家庭配备了空气净化器,但他们缺乏正确使用空气净化器的基本知。因此,关于空气净化器的研究应该引起更多关注,以确保所有人都能受益。2017年的一个调查发现约81.4%的被调查住户根本不使用配备的空气净化器,空气净化器控制PM2.5浓度的能力没有得到充分发挥。如果空气净化器的运行可以实现自动化,便可以更好地控制室内PM2.5浓度,降低PM2.5暴露的健康风险。
强化学习是探索多目标优化控制策略的有效途径。它对随机过程具有较好的适应性,可以从室内状态数据中确定平衡能耗和室内空气质量的最佳控制策略。本工作的新颖之处在于:1. 建筑参数的测量和计算来源于真实的建筑测量项目,更接近于本研究对象的实际情况;2. 本研究考虑了空气净化器的不同模式,更接近于现实生活中的情况;3. 本文采用的随机污染源强度和随机空气交换率的方法能够反映人类活动的随机性。
本研究的目的是:1)建立一个随机模型来描述自然通风家庭的室内空气质量过程;2)建立强化学习模型,优化空气净化器的控制策略;3)在真实情况下评价基于强化学习的运行策略的能效和控制效果。
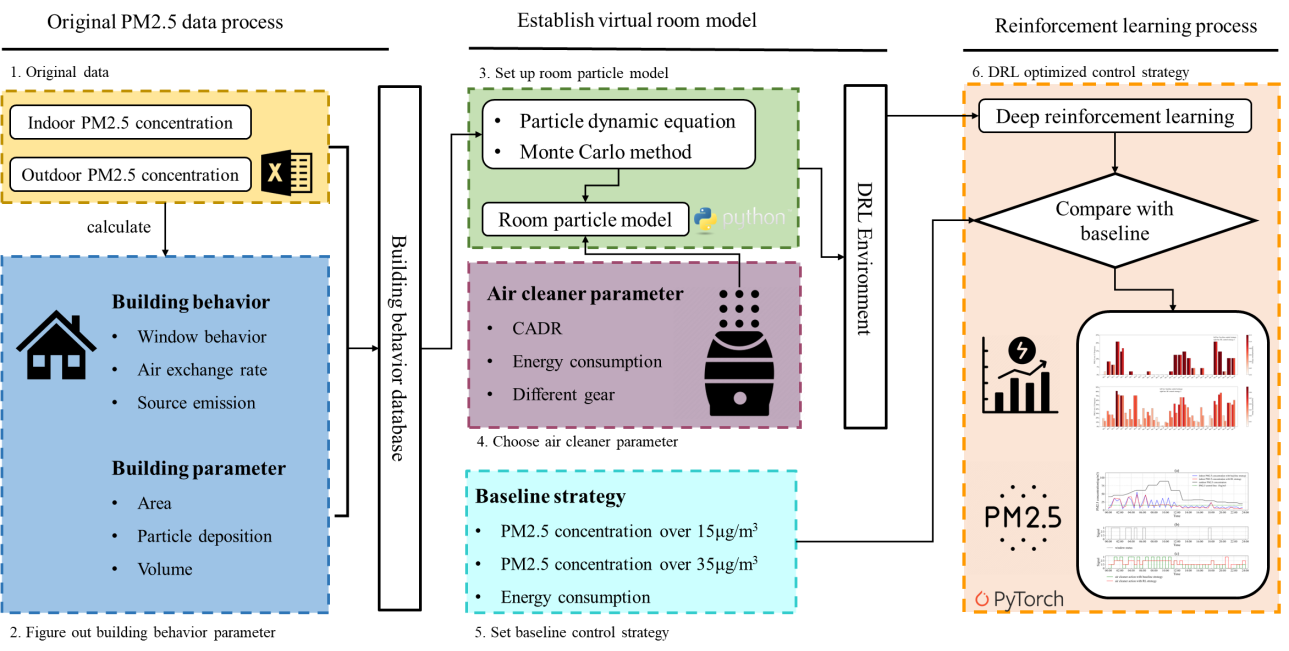
Fig. 1. General framework of this study from original data to control strategy based on reinforcement learning
图1. 本研究的总体框架:从原始数据到基于强化学习的控制策略
1. 开发了一种加入基于蒙特卡洛模拟的房间IAQ过程模型的强化学习框架,形成了控制策略训练闭环
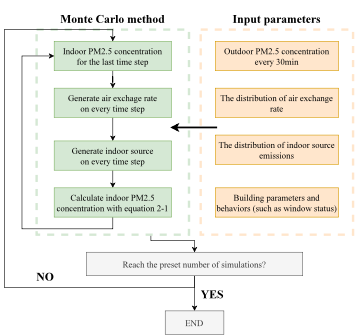
Fig. 2. Monte Carlo method detailed process
图2. 蒙特卡洛方法的详细过程
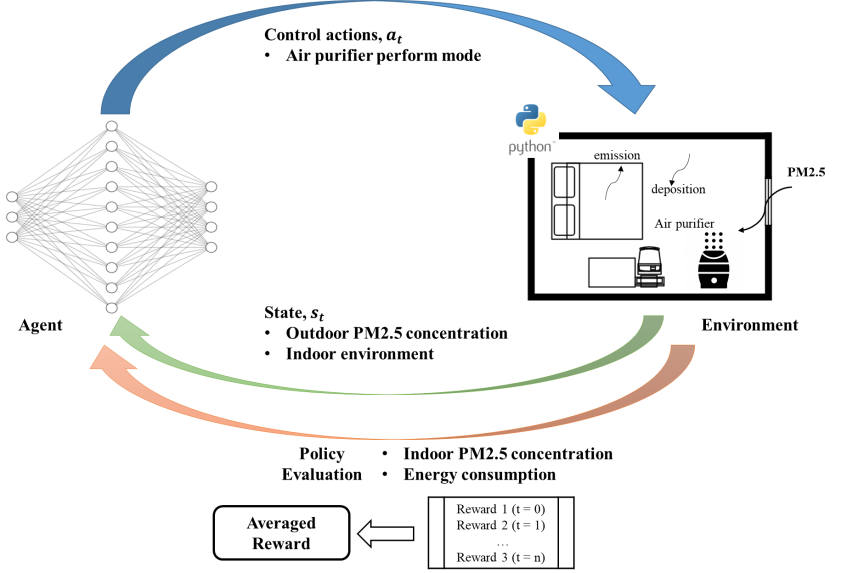
Fig. 3. Framework for apartment control of air purifier. Deep Q-learning is used and the agent outputs optimal action to the environment for each time step
图3. 公寓空气净化器控制框架。使用深度Q -学习,智能体为每个时间步向环境输出最佳动作
在本研究中,训练强化学习中的智能体(agent)控制空气净化器的行为,包括打开,关闭和不同运行模式。环境为本研究建立的虚拟房间模型,环境所提供的状态为室内PM2.5浓度和空气净化器能耗。虚拟房间中带有随机性的IAQ过程使用蒙特卡洛方法进行模拟。
2. 基于测试数据得到了真实建筑中源强度,空气交换率和开关窗的频率分布,并验证了该模型的准确性
根据以往文献和一些新的数据处理方法对以往在天津的长期真实测试数据进行再次处理,得到了关于开关窗,建筑物中源释放强度和时间以及空气交换率的频率分布,并作为训练环境的随机输入数据对控制策略进行训练。
通过一周的数据验证了该模型对于真实建筑行为模拟的准确性。
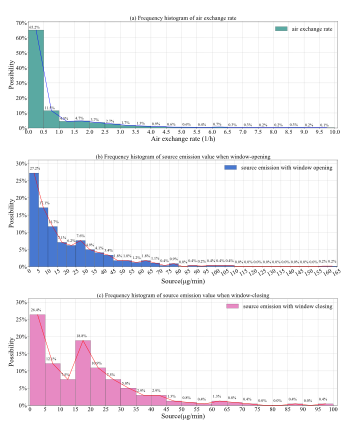
Fig. 4. Frequency histogram of air exchange rate and indoor source emissions
图4. 空气交换率与室内源排放频率直方图
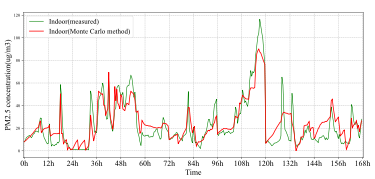
Fig. 5. 7 days indoor PM2.5 concentration comparison between measured data and predicted data
图5. 7天室内PM2.5实测值与预测值对比
3. 基于深度强化学习开发了两种空气净化器智能控制策略,相较于基准控制策略具有更好的控制效果。
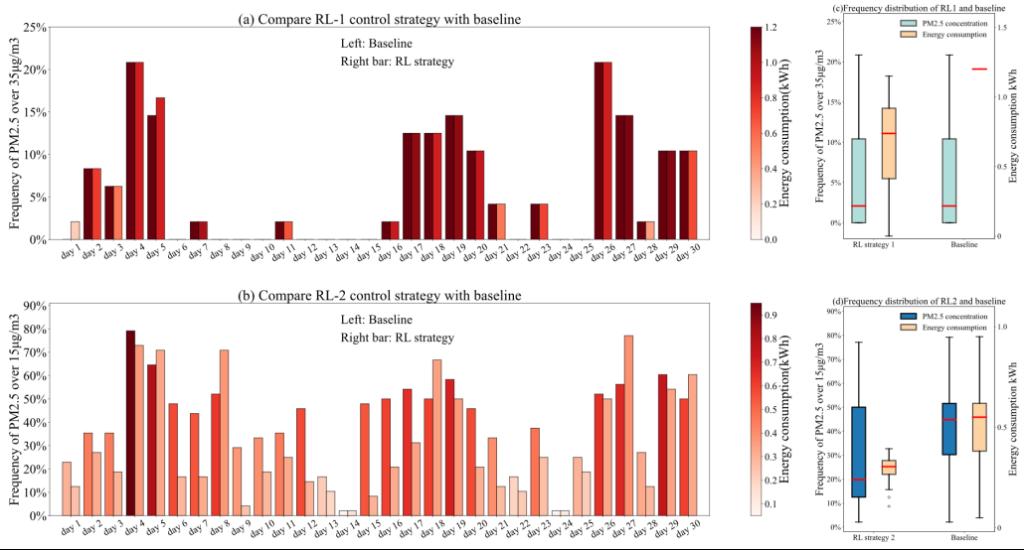
Fig. 6. Energy and PM2.5 concentration level comparison between baseline and RL strategies (a)Comparison of RL-1 and baseline control effect, (b)Comparison of RL-2 and baseline control effect, (c) Daily frequency of indoor PM2.5 concentration exceeds control standard and energy consumption under RL-1 and baseline, (d) Daily frequency of indoor PM2.5 concentration exceeds control standard and energy consumption under RL-2 and baseline
图6. (a) RL-1与基线控制效果比较,(b) RL-2与基线控制效果比较,(c) RL-1与基线下室内PM2.5浓度日超标频率及能耗,(d) RL-2与基线下室内PM2.5浓度日超标频率及能耗
两种智能控制策略均在室内PM2.5浓度控制和能效方面具有优势,并且提升效果较为明显。
4. 分析了强化学习具有更好控制效果的原因,对典型天进行分析并解释了RL的控制策略
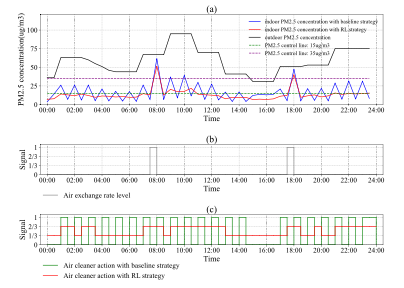
Day 7
Fig. 7. Comparison of indoor PM2.5 concentration and air purifier performance on a typical day under baseline control strategy and RL-2 strategy
图7. 基线控制策略和RL-2策略下典型日室内PM2.5浓度和空气净化器性能的比较
通过对随机的开窗情况,内源情况和室外PM2.5浓度等因素的适应,深度强化学习可以很好的考虑此刻的行为对整体控制效果的影响,相比于仅根据室内浓度调整行为的基线策略,RL达到了更加稳定的控制效果,使室内PM2.5浓度维持在较低的浓度内,且波动较小,根据训练数据预测未来室外浓度,并提前做出相应的动作可以降低室内PM2.5浓度的峰值。
5. 对训练的智能控制器进行了鲁棒性研究
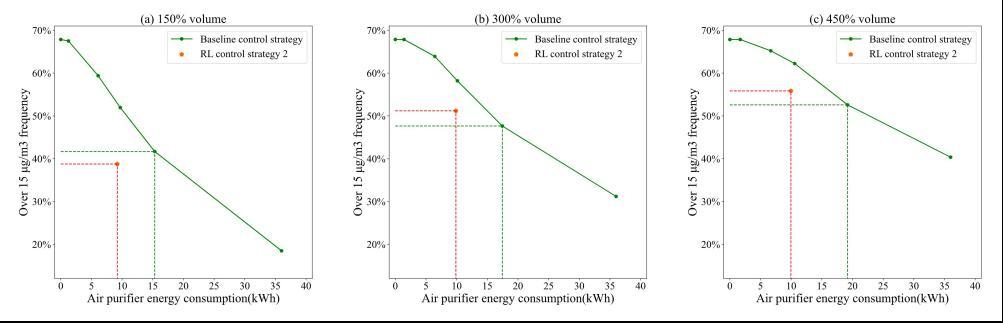
Fig. 8. Trained RL-2 control effect in different room volume (a) Comparison of RL-2 and baseline control strategy under 150% room volume bigger than trained environment, (b) Comparison of RL-2 and baseline control strategy under 300% room volume bigger than trained environment, (c) Comparison of RL-2 and baseline control strategy under 450% room volume bigger than trained environment
图8. 不同房间容积下训练后的RL-2控制效果(a)房间容积是训练环境的150%时RL-2与基线控制策略的比较,(b)300%时RL-2与基线控制策略的比较,(c)450%时RL-2与基线控制策略的比较
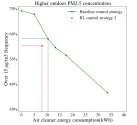
Fig. 9. Comparison of RL-2 and baseline control strategy with higher PM2.5 concentration than the trained environment
图9. PM2.5平均浓度(97.30μg/m³)高于训练环境(58.19μg/m³)时RL-2与基线控制策略的比较
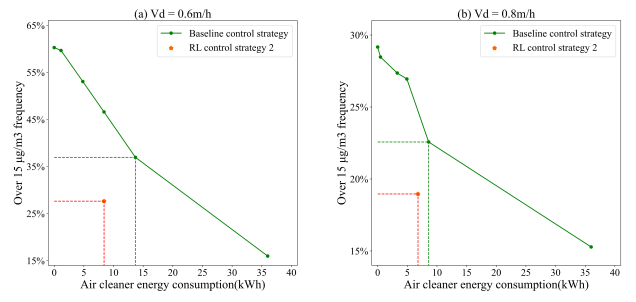
Fig. 10. Comparison of RL-2 and baseline control strategy in different particle deposition velocity (a) vd = 0.6m/h, (b) vd= 0.8m/h
图10. 不同颗粒沉积速度下RL-2与基线控制策略的比较(a) vd = 0.6m/h, (b) vd= 0.8m/h
一些因素可能会降低模型的效果,如颗粒沉降速度、人的随机活动、室外PM2.5浓度等。如图13所示,在一定范围内,室外PM2.5浓度的增加并不会导致模型“失效”。但是,如果PM水平与训练数据偏差很大,则可能导致模型“失效”。同时,该模型也适用于有限的房间体积范围,当房间的体积超过训练数据中房间体积的3倍时,该模型将失去效果。
W. Shang, J. Liu, C. Wang, J. Li, X. Dai, Developing smart air purifier control strategies for better IAQ and energy efficiency using reinforcement learning, Building and Environment (2023), doi: https://doi.org/10.1016/j.buildenv.2023.110556
编辑人:商文哲
审核人:刘俊杰、田媛、何明桐

