
时间:2023-09-16 点击量:

课题组王延敏博士在中科院一区期刊《Energy》(JCR Q1, IF= 8.857)发表了论文,以提升供热舒适性及节能目标,研究了基于数据驱动的集中供热系统室内特征温度(ICTS)分析与预测。
1. 题目
Data-driven analysis and prediction of indoor characteristic temperature in district heating systems
基于数据驱动的集中供热系统室内特征温度分析与预测
2. 作者
Yanmin Wang(王延敏,一作,天大/大连海心),Zhiwei Li(李志伟,天大),Junjie Liu(刘俊杰,通讯作者,天大),Mingzhe Pei(裴明哲,唐山热力),Yan Zhao(赵岩,大连海心),Xuan Lu(鲁轩,大连海心)
3. 研究亮点
lICTS可以评估供热质量,并用于集中供热系统的反馈控制。
l提出了一种基于熵值法的ICTS计算方法。
l所提出的方法能够更好地反映数据的综合特性。
l使用SVR、LR、XGBoost、RF和GBM模型对ICTS进行预测。
l当对原始数据去噪时,LR模型表现最好,MAPE为0.12%。
4.研究背景
室内温度是影响人体热舒适性和集中供热系统节能的主要因素之一。由于户端缺少调控设备,国内集中供热系统的调节都是在换热站进行的,无法实现对室内温度、热水流量等参数的精确控制。室内温度是评价供热质量的标准,调控的最终目标是确保室内温度达到政府规定的目标值。随着物联网和信息技术的快速发展,很多建筑物的房间安装了室内温度采集器,安装数量一般占总用户数量的2%-10%。一个换热站对应的室内温度有多个,不能直接用作换热站的调控参数。因此,需要根据多个房间的室内温度来计算换热站的室内特征温度(ICTS)。
传统的ICTS计算方法包括简单平均法、中值法和以目标值为标准的加权平均法。由于水力和热力条件的综合影响,不同条件下供热参数对室内温度的影响不同,这些方法不能准确地评估换热站室内温度的综合特性。熵描述了空间中能量分布的不确定性,可以用来表示系统的无序程度。室内温度采集器位于建筑物中的不同位置和管网的不同阶段,不同采集器测得的室内温度并不相同;即使同一个采集器,测量的室内温度也会因热用户活动的影响而波动。因此,室内温度存在波动现象,其波动程度可由熵值表示,因此可借助熵值法来计算每个室内温度采集器在ICTS中的权重。波动增加,熵值增加,权重减小。波动减小,熵值减小,权重增大。
由于算法和计算能力的提高,基于数据驱动的机器学习算法在集中供热系统研究中得到了广泛应用。典型的案例包括热负荷预测、供/回水温度预测、热响应时间预测和热用户端室内温度预测等。为更加深入理解特征参数对供热效果的影响程度,可借鉴以往的研究成果对ICTS进行预测。
5.主要成果
5.1 提出了研究流程
本研究的处理流程分为四个步骤:(1)从三个实际的集中供热系统收集了原始数据。(2)对原始数据进行预处理,包括异常值检测、数据去噪和缺失数据填充。(3)使用多种方法计算ICTS并进行比较。(4)选择了五个经典的算法模型对ICTS进行预测。
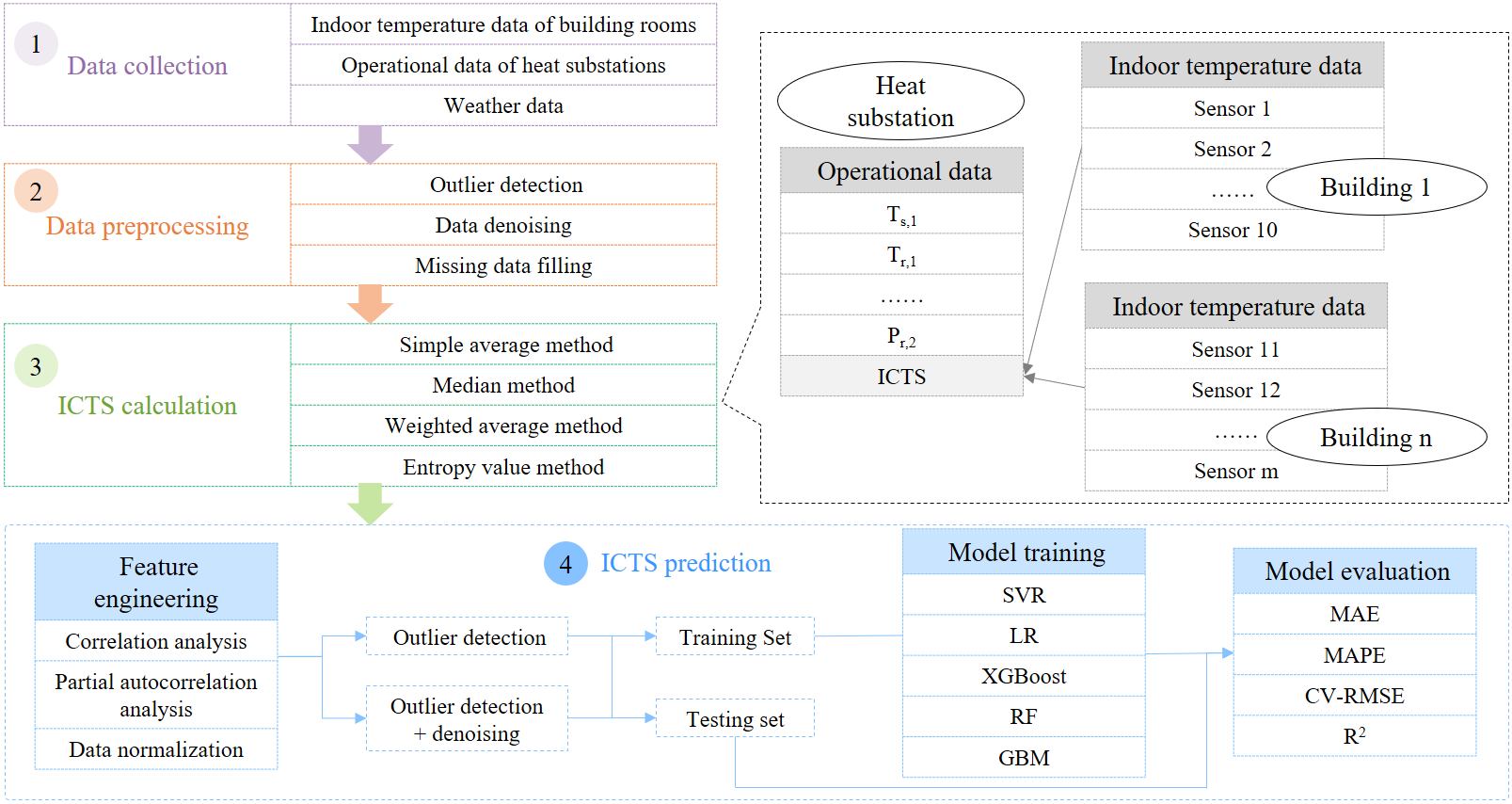
Fig. 2. Process of this study.
图2 本研究的处理流程
5.2 试验对象选择
本研究选择了三个中国北方的集中供热系统作为试验场地,分别位于辽宁大连、吉林长春和河北唐山。从每个集中供热系统各选择了一个换热站作为试验对象,其供热面积、热用户数量和室温采集器数量如图3所示。
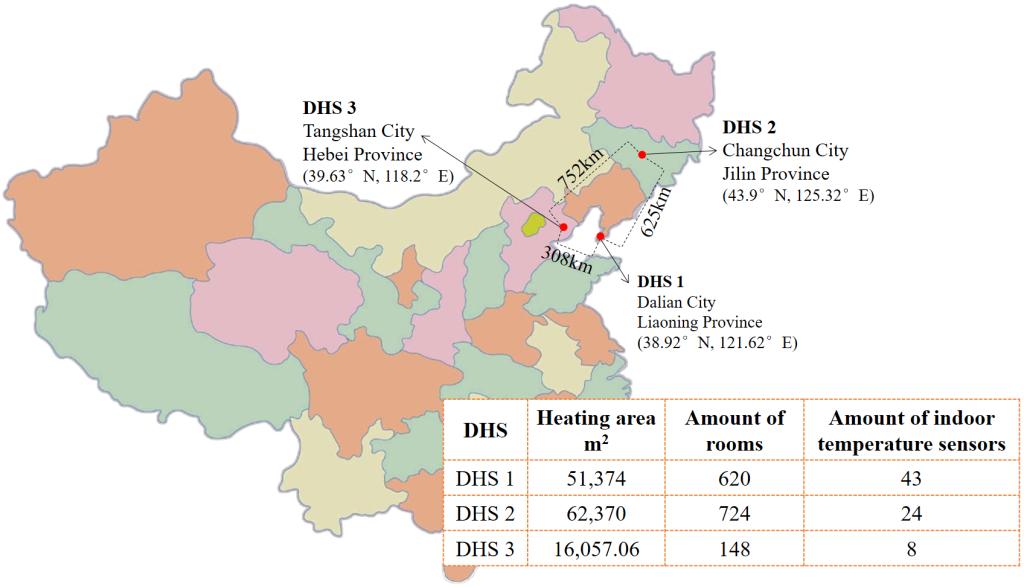
Fig. 3. Location and information of the three DHSs.
图3 三个集中供热系统的位置和相关信息
5.3 试验数据收集
试验数据为三个换热站完整采暖季的室内温度数据、换热站运行数据和天气数据。室内温度数据采样周期分别为15/30/20分钟。换热站运行数据包括10个特征,每小时采集一次。天气数据包括7个特征,每小时采集一次。
5.4 室温数据分析
从每个数据集中提取三个室内温度采集器的部分数据进行观察,如图5所示。结果表明,室内温度不仅受共同因素(天气条件、换热站控制参数)的影响,还受建筑围护结构和热用户活动等更多独立因素的影响。
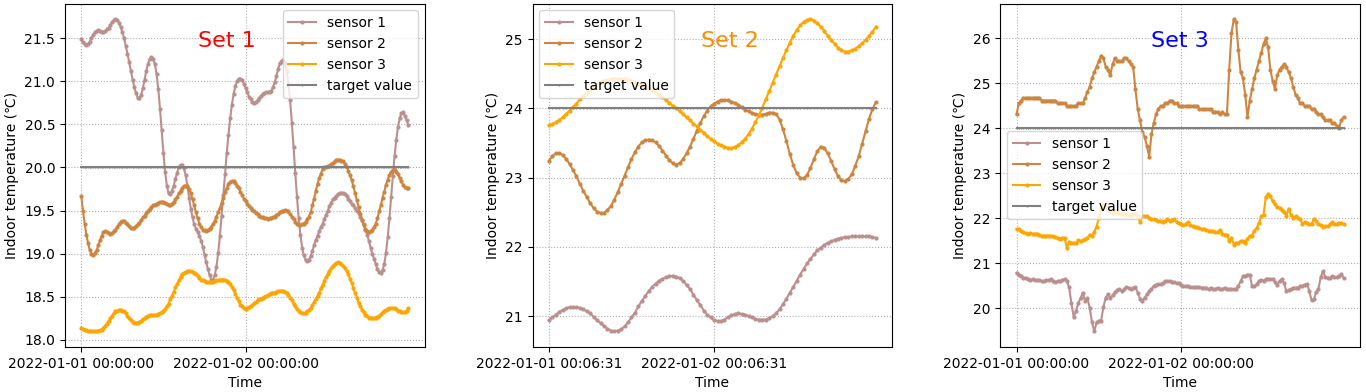
Fig. 5. Example of indoor temperature data details.
图5 详细室温数据示例
上述情况也存在于长期数据趋势中,计算了上述九个传感器整个采暖季数据每小时的平均值,如图6所示。
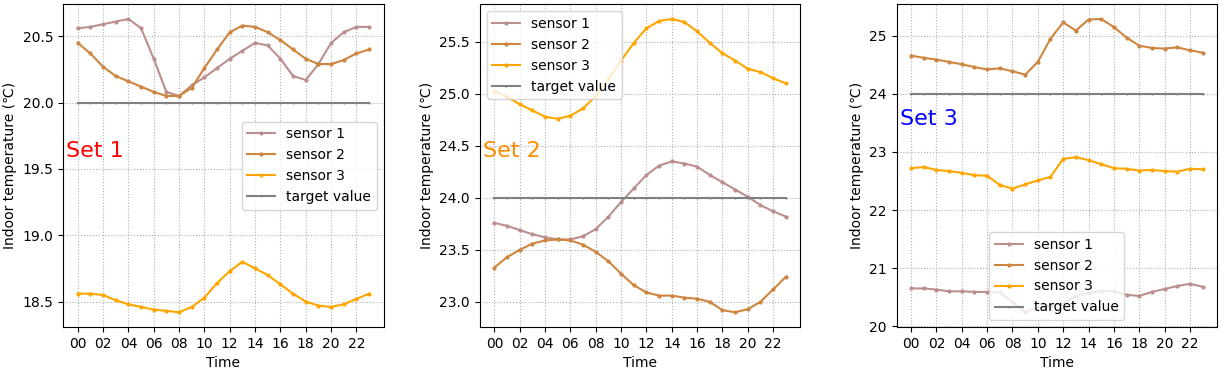
Fig. 6. Example of long-term indoor temperature data.
图6 长期室内温度数据示例
5.5 ICTS的计算与比较
采用四种计算方法对ICTS进行了计算,包括简单平均法(SA)、中位数法(MD)、以供热目标值为标准的加权平均法(WA)和熵值法(EV)。结算结果的分布范围如图8所示。
EV方法基于每个室内温度采集器的测量值的变化程度来确定加权系数,而无需预先设置偏好,并更多地考虑了不确定性信息。因此,使用EV方法获得的加权系数更好地反映了数据的特性,消除了主观偏好的影响。
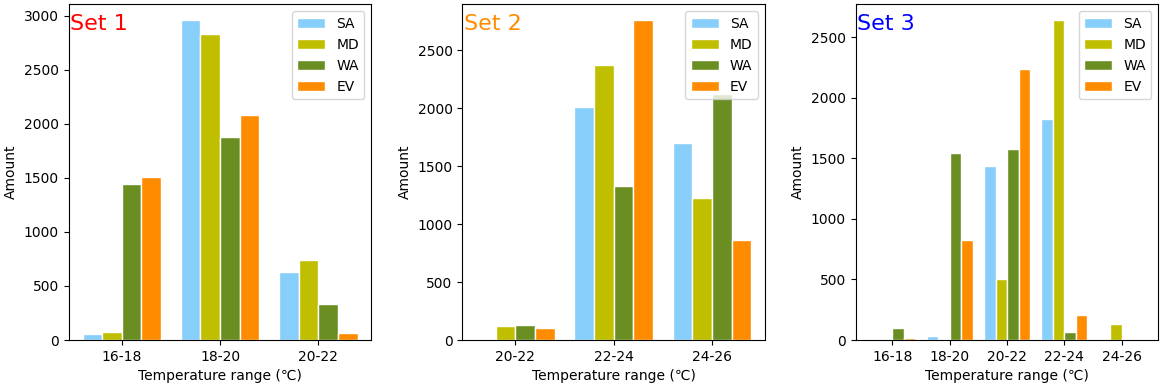
Fig. 8. Distribution of the amount of the ICTS in various temperature ranges.
图8 ICTS在不同温度范围内的分布
5.6 ICTS的预测
采用五个经典的算法模型对ICTS进行了预测,包括SVR、LR、XGBoost、RF和GBM。采用四种指标MAE、MAPE、CV-RMSE和R2对预测性能进行了评估。原始数据分别采用两种方法进行了预处理,第一种只采用3σ方法检测异常;第二种在3σ方法检测异常的基础上,还采用CEEMDAN方法进行了去噪。预测结果如表7所示。
Table 7 Prediction results of ICTS.
表7 ICTS的预测结果
Dataset |
Model |
Without CEEMDAN |
With CEEMDAN |
||||||
MAE |
MAPE% |
CV-RMSE% |
R2 |
MAE |
MAPE% |
CV-RMSE% |
R2 |
||
Set 1 |
SVR |
0.09 |
0.48 |
0.60 |
0.86 |
0.05 |
0.26 |
0.34 |
0.96 |
LR |
0.08 |
0.45 |
0.58 |
0.87 |
0.04 |
0.21 |
0.27 |
0.97 |
|
XGBoost |
0.09 |
0.48 |
0.63 |
0.85 |
0.05 |
0.28 |
0.35 |
0.95 |
|
RF |
0.09 |
0.47 |
0.60 |
0.86 |
0.05 |
0.29 |
0.36 |
0.95 |
|
GBM |
0.08 |
0.45 |
0.58 |
0.87 |
0.05 |
0.27 |
0.34 |
0.95 |
|
Set 2 |
SVR |
0.11 |
0.44 |
0.56 |
0.93 |
0.05 |
0.21 |
0.25 |
0.99 |
LR |
0.09 |
0.35 |
0.44 |
0.96 |
0.02 |
0.08 |
0.10 |
0.99 |
|
XGBoost |
0.09 |
0.39 |
0.50 |
0.94 |
0.04 |
0.17 |
0.21 |
0.99 |
|
RF |
0.08 |
0.34 |
0.44 |
0.96 |
0.04 |
0.16 |
0.20 |
0.99 |
|
GBM |
0.09 |
0.39 |
0.49 |
0.95 |
0.04 |
0.17 |
0.20 |
0.99 |
|
Set 3 |
SVR |
0.10 |
0.48 |
0.65 |
0.91 |
0.04 |
0.19 |
0.25 |
0.98 |
LR |
0.09 |
0.42 |
0.62 |
0.92 |
0.01 |
0.07 |
0.09 |
0.99 |
|
XGBoost |
0.11 |
0.51 |
0.66 |
0.90 |
0.04 |
0.18 |
0.24 |
0.99 |
|
RF |
0.10 |
0.47 |
0.63 |
0.91 |
0.03 |
0.15 |
0.20 |
0.99 |
|
GBM |
0.11 |
0.51 |
0.69 |
0.90 |
0.04 |
0.20 |
0.25 |
0.98 |
|
5.7 两种数据预处理方法的预测性能比较
使用CEEMDAN预处理后数据的预测性能远优于使用未预处理数据,如图9所示。原始数据是高度非线性的。CEEMDAN预处理后的数据降低了噪声,提高了平滑度,使其更加线性。各种预测模型对线性数据的处理能力优于对非线性数据的处理,因此,CEEMDAN预处理后的数据预测性能较好。
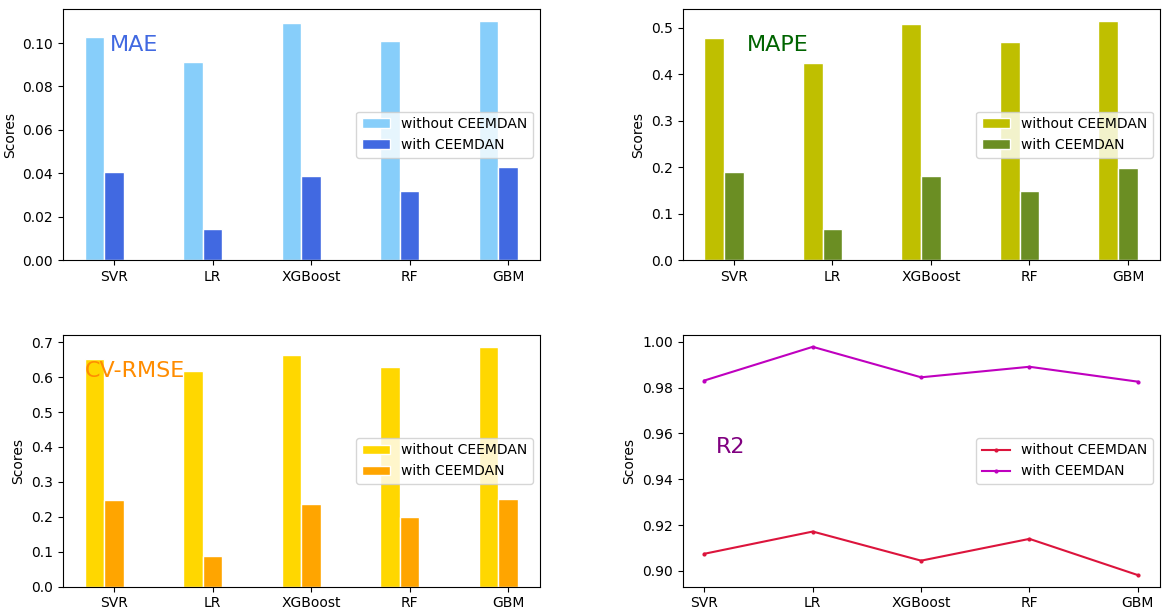
Fig. 9. Comparison of the performance of the two preprocessing methods for Set 3.
图9 两种预处理方法的性能比较,以数据集3为例
5.8 三个数据集的预测性能比较
数据集2和3的预测性能优于数据集1。以CEEMDAN预处理的SVR模型为代表,各种评估指标的比较如图10所示。
集中供热系统1的调控策略采用室温反馈控制,设定ICTS的目标值,并依据实际值调节换热站的供热参数。数据集1的ICTS受换热站运行数据的影响更大,非线性更强。在集中供热系统2和3中,ICTS只是用来评估供热质量,换热站的调节只是依据室外气象参数。数据集2和3的ICTS受换热站运行数据的影响较小,线性更强。因此,在ICTS的预测中,数据集1比数据集2和3受更多特征的影响,非线性更强,预测精度较低。
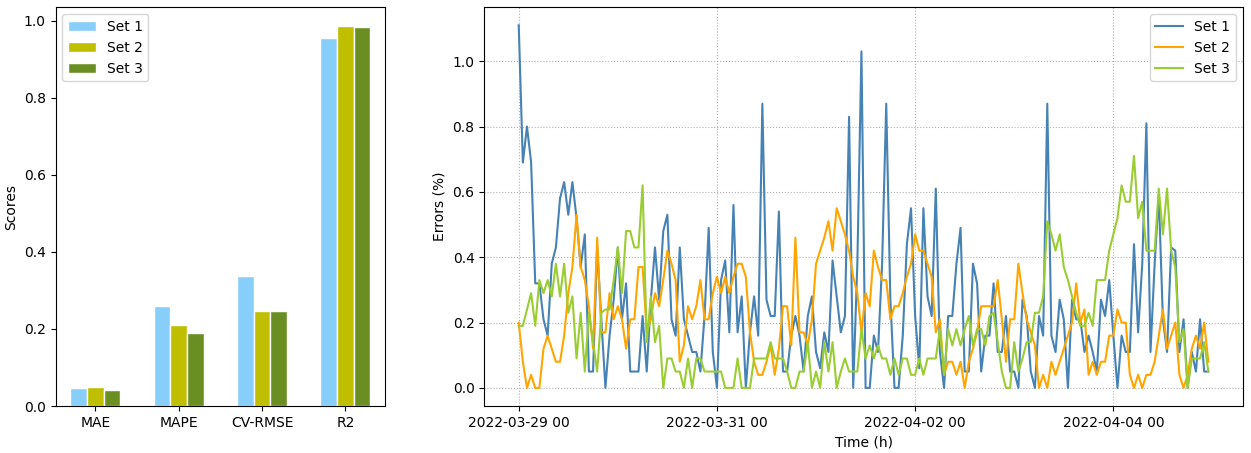
Fig. 10. Comparison of the performance of the three datasets for SVR.
图10 三个数据集的性能比较,以SVR模型为例
5.9 五种模型预测性能的比较
五个模型在三个数据集和两种数据预处理方法下表现出不同的预测性能。以数据集3为示例,五种模型的预测性能如图11所示。当CEEMDAN用于数据预处理时,LR模型的性能优于其他模型,次优模型是RF模型,GBM、SVR和XGBoost模型的预测性能相似。当CEEMDAN方法不用于数据预处理时,GBM、RF和LR模型是最优的。
LR模型适用于拟合简单的线性数据,而GBM模型对复杂的非线性数据具有良好的处理能力。在本研究中,数据集1具有最强的非线性,CEEMDAN预处理提高了数据的线性。因此,当CEEMDAN用于数据预处理时,LR模型表现最好;而当不使用时,GBM对数据集1表现最好。
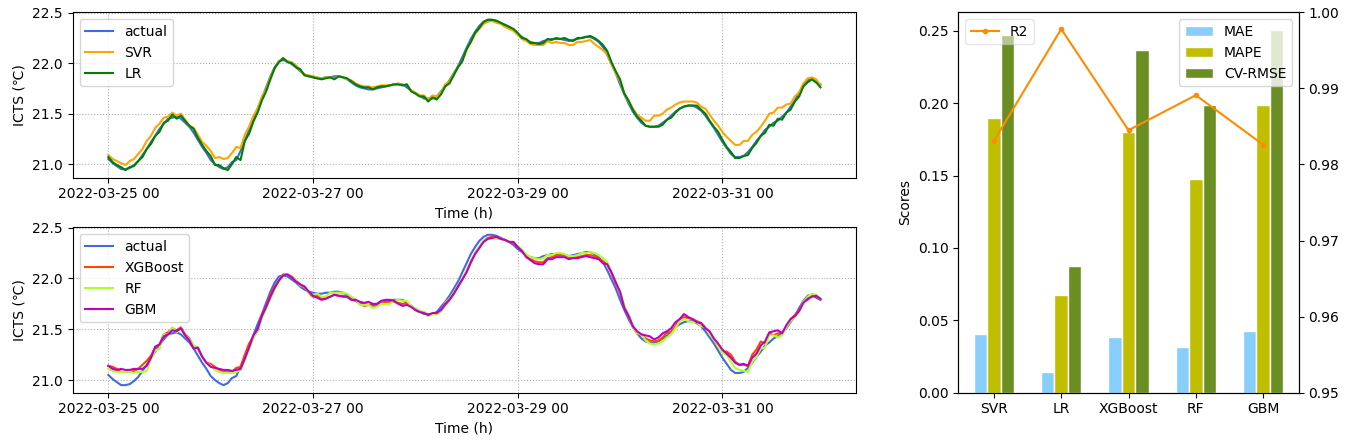
Fig. 11. Comparison of the performance of the five models for Set 3.
图11 五种预测模型的性能比较,以数据集3为例
文章引用格式:
Yanmin Wang, Zhiwei Li, Junjie Liu, Mingzhe Pei, Yan Zhao, Xuan Lu. Data-driven analysis and prediction of indoor characteristic temperature in district heating systems. Energy 2023;282:129023. https://doi.org/10.1016/j.energy.2023.129023.
稿件编辑:王延敏
稿件审核:刘俊杰、田媛、何明桐

